안녕하세요. 처음으로 논문 리뷰 글을 작성하게 되었습니다. 이번에 소개해 드릴 논문은 "Representation Learning with Contrastive Predictive Coding" 논문입니다. Contrastive Predictive Coding(CPC)은 unlabeled data로부터 유용한 representation을 학습할 수 있고, 여러 domain에 적용할 수 있다는 장점이 있습니다. 처음 작성하는 리뷰이기 때문에 아직 부족한 부분이 많을 것이라고 생각합니다. 혹시 잘못된 점이나 질문이 있다면 댓글 남겨주시면 감사하겠습니다!
Abstract
논문에서 Contrastive Predictive Coding, 즉 high-dimensional data로부터 유용한 representations을 추출하기 위한 unsupervised learning approach을 제안하였습니다. 제안한 모델의 핵심은 autoregressive model을 이용하여 latent space에서 미래 값을 예측함으로써 유용한 representations을 학습하는 것입니다. 논문에서 제안한 접근법은 4개의 도메인(speech, images, text, reinforcement learning)에서 좋은 퍼포먼스를 달성하면서 유용한 representations을 학습할 수 있었다고 말합니다.
Introduction
지도 학습(Supervised learning)에서 레이블 된 데이터를 이용하여 high-level representation을 학습하는데 큰 성과가 있었습니다. 하지만 지도 학습은 한 supervised task에 특화되어 있습니다. Representation learning을 향상시키기 위해선 한 가지 supervised task을 해결하는 것이 아닌 여러 task에 적용할 수 있는 일반적인 features을 필요로 합니다. 그래서 한 모달리티(이미지, 자연어 등)에 특화된 지도 학습은 한계가 있습니다. 이러한 문제점은 비지도 학습(unsupervised learning)에서도 나타나지만 지도 학습보다는 한 task에 덜 specialized 하므로 레이블링 없이 유용한 representation vector을 생성할 수 있게 학습을 합니다. (비지도 학습은 데이터의 패턴이나 형태를 찾는데 사용됨)
비지도 학습의 보편적인 전략 중 하나는 미래 값이나 결측치, 문맥 정보(contextual information)를 예측하는 것이고(이를 predictive coding이라 함), 최근 학습 방식도 이 아이디어를 사용하고 있습니다. 논문에서 제안하는 방식은 다음과 같습니다.
1. High-dimensional data을 더 compact 한 latent embedding space로 압축하여 모델이 conditional prediction을 더 수행하기 쉽도록 합니다.
2. Latent space에서 강력한 autoregressive model을 사용하여 미래의 값을 예측합니다.
3. 자연어에서 단어 임베딩을 학습하기 위해 사용되어 온 것과 비슷하게 loss function에 Noise-Contrastive Estimation을 접목합니다. 이는 전체적인 모델이 end-to-end로 학습이 가능하도록 합니다.
Motivation and Intuitions
논문의 목적이 비지도 학습을 이용해(autoregressive model을 이용하여 latent space에서 미래 값을 예측함으로써) 유용한 representation을 학습하는 것임을 다시 한번 말하고 갑니다. 비지도 학습에서 미래의 값을 예측할 때 데이터 전반에 공유된 정보의 양은 적어지고, 이로 인해 모델은 좀 더 global structure을 추론할 필요가 있게 됩니다. 이를 slow features(이미지에서의 물체, 책의 스토리, 스피치에서의 억양 등)라 합니다. 즉 비지도 학습에서 데이터의 각 부분, 시점들이 공유하고 있는 글로벌한 특징들에 대해서 주목하게 학습하여 미래의 값을 예측하려 하는데 이때 딥러닝이 뽑아내는 features가 representation을 잘 나타내는 slow features라고 할 수 있습니다.
이런 High-dimensional data, high-level information를 예측함에 있어 강력한 conditional generative model이 필요합니다. 하지만 생성 모델은 데이터 x에서 복잡한 관계를 모델링 하는데 많은 시간이 소요되고 컴퓨터 용량을 낭비하게 됩니다. 그리고 종종 context c를 무시하게 됩니다(고차원 정보를 가진 이미지를 생성할 때 class label은 훨씬 적은 정보를 담고 있음. 즉 많은 정보를 가지고 있는 x 대비 class label c가 훨씬 적은 정보를 갖고 있어 둘이 공유하는 정보를 뽑아내기 어려움).
따라서 직접적으로 p(x|c)를 모델링 하는 것은 x와 c 사이의 공유된 정보를 추출하는 목적에 적합하지 않습니다.
그래서 future information을 예측할 때 타겟 x(미래 값)과 context c(현재 값)을 compact 하게 distributed vector representation으로 인코딩합니다. 이때 x와 c의 상호의존정보(mutual information)를 최대한 보존하도록 학습합니다. 즉 encoded representation사이의 상호의존정보를 최대화함으로써 input들이 공통적으로 갖고 있는 latent variable들을 추출해 냅니다.

이때 상호의존정보는 한 변수가 다른 변수에 얼마나 dependent 한 지 나타내는데 두 변수가 dependent 할수록 값은 커지게 됩니다. 즉 값이 클수록 x, c 가 서로에게 제공하는 정보의 양이 많다는 것입니다.
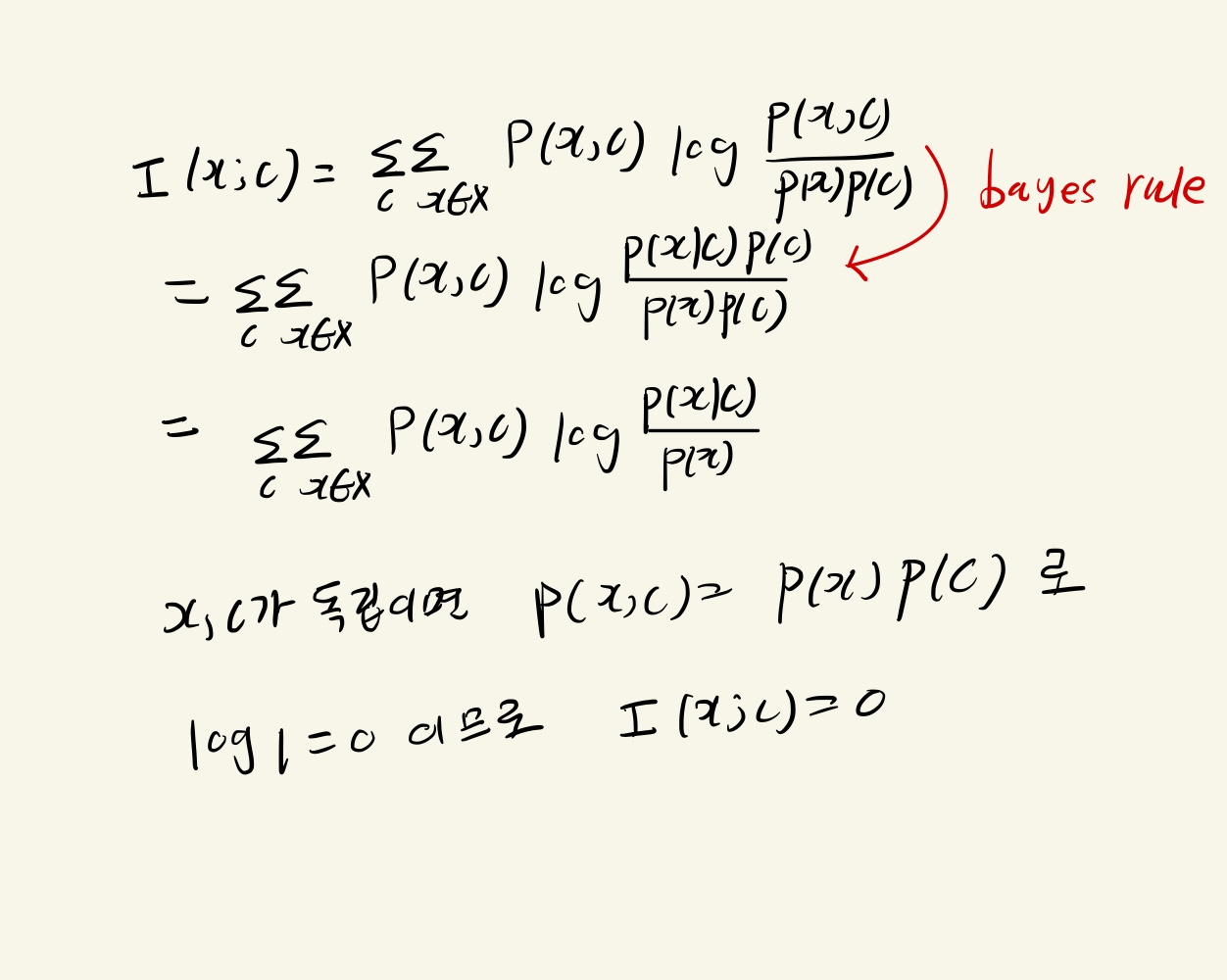
Contrastive Predictive Coding

Figure 1은 Contrastive Predictive Coding의 구조를 보여줍니다.
1. 비선형 인코더 g_enc는 입력 sequence x_t를 latent representation인 z_t로 매핑합니다.

2. autoregressive model인 g_ar이 과거 시점의 (z_0, z_1, ---, z_t-1, z_t)를 입력으로 하여 context latent representation c_t를 생성합니다.
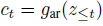
이 때 미래 관측값인 x_(t+k)를 생성 모델을 이용해 직접적으로 생성하는 것이 아닌 미래 예측값 x_(t+k)과 context 벡터 c_t사이의 mutual information에 비례하는 density ratio을 모델링합니다. 즉 함수 f_k는 상호의존정보에 비례하도록 설계하고 정보를 최대화 하는 방향으로 학습합니다.

저자들은 simple log-bilinear model을 사용하였는데 이 모델에 대한 지식이 없어 "Rethinking representations: A log-bilinear model of phonotactics" 논문을 참고하였습니다.
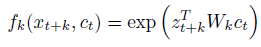
z_(t+k) 는 x_(t+k)의 latent vector이고 c_t는 t시점의 context vector입니다. z_(t+k) 와 c_t의 행렬곱은 유사도를 나타내고 이때 W_k는 거리k에 따른 interaction matrix입니다. 이 matrix는 c_t 가 어떻게 z_(t+k)와 연관되어 있는지를 나타냅니다. 즉 k값에 따라 matrix 값이 달라질 것입니다. 다음으로 loss 함수를 정의하여 학습이 진행되는 과정을 알아보도록 하겠습니다.
Noise Contrastive Estimation(NCE)
InfoNCE을 알기 위해선 먼저 Noise Contrastive Estimation(NCE)에 대해서 알아야 합니다.
자연어 task에서 문장의 빈칸(타겟)을 예측하는 task을 할 때로 예를 들어봅시다.

이 때 target 은 '도쿄로' 이고 softmax 함수를 이용하여 다음과 같이 확률 값을 추출하게 됩니다. 학습을 진행하면 '도쿄로' 의 결괏값은 제일 클 것이고 연관된 단어들일수록 결괏값이 클 것입니다.

| softmax | label | |
| 도쿄로 | 0.7 | 1 |
| 서울로 | 0.1 | 0 |
| 베이징으로 | 0.8 | 0 |
| … | … | 0 |
학습 시 문제점은 training examples의 각 단어의 softmax 값을 구할 때 항상 같은 분모를 가지게 되어서, 학습을 시켜줘야 하는 파라미터가 모든 training examples에 대해서 non-zero gradient term을 가지게 됩니다. 빈칸에 '바나나로' 등과 같이 빈칸에 들어갈 확률이 0에 가까운 단어들도 training examples에 포함시킨다면 학습에 비효율적일 것입니다. 그래서 모든 단어를 고려하는 것이 아닌 일부 단어만을 이용해 학습을 할 것입니다. 학습에 이용할 non-target 단어를 추출할 것인데 이렇게 추출된 샘플을 negative sample라 하고 target 단어를 positive sample이라 합니다. NCE 논문에서 true target을 1 negative samples(noise)는 0으로 설정합니다. 논문에서 logistic regression 모델링을 이용하는데, target word distribution P와 noise distribution Q라 하면 logit은 다음과 같습니다.

이 logit은 input이 분포 P에서 왔을 확률과 Q에서 왔을 확률의 비인 odds에 log를 씌운 것입니다. 이때 Q는 알려진 분포에서 추출한 것이고 logit을 이용해 P의 분포를 알아내도록 학습합니다. 이 개념을 이용하여 infoNCE loss를 정의하게 됩니다.
InfoNCE Loss and Mutual Information Estimation
InfoNCE Loss는 다음과 같이 정의됩니다. 이 때 N개의 random samples에서 하나는 positive sample이고 N-1개는 negative sample입니다.
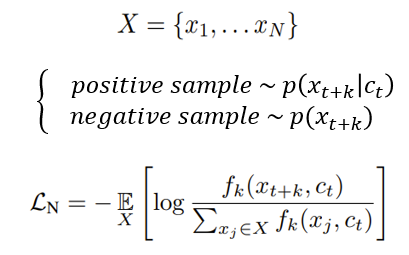
이 손실함수를 살펴보면 positive sample을 알맞게 분류하는 categorical cross-entropy 형태를 하고 있고, log안의 값은 모델의 prediction입니다. 이 손실함수를 optimizing 즉 최소화하기 위해선 log 안의 식 prediction을 최대화, 즉 분모를 최대화하여야 하고 이는 mutual information에 비례하도록 설계하였으니 mutual information을 최대화한다는 것으로도 이해를 할 수 있습니다. 모델이 예측하는 값이 mutual information에 비례한다는 것을 저자들은 다음과 같이 보였습니다. 저자들은 손실함수에 대한 optimal probability을 다음과 같이 나타내었습니다.

이 때 (d = i)는 sample x_i가 positive sample이라는 것을 나타냅니다. 도출 과정을 간단히 제시하겠습니다.

이를 통해서 모델이 예측하는 값이 mutual information에 비례하고, negative sample수에 독립적인 것을 확일할 수 있습니다.

mutual information의 lower bound는 다음과 같이 도출됩니다.
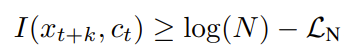
이를 통해서 알 수 있는 것은 infoNCE loss N을 최소화할수록, sample 수를 증가시킬수록 lower bound는 증가하게 됩니다. 그래서 저자들은 sample수 N을 늘리면 유용하다고 언급하였습니다. lower bound는 다음과 같이 도출됩니다.

Experiments
저자들은 speech, image, natural language, reinforcement learning domain에 대해서 실험을 진행하였습니다.
natural language 만 살펴보겠습니다. 다른 domain에 대한 결과가 궁금하시면 논문을 참고하시길 바랍니다. 저자들은 BookCorpus 데이터 셋에 대해 모델을 학습시키고, CPC representation을 사용하여 generic feature extractor로써 모델을 평가하였습니다. 학습과정에서 사용이 안 된 단어들에 대해 대비하기 위해서 word2vec과 모델에 의해 학습 된 word embeddings 사이에 linear mapping을 추가로 구축하였습니다.
classification task을 위해 movie review sentiment (MR), customer product reviews (CR), subjectivity/objectivity, opinion polarity (MPQA), question-type classification (TREC) 데이터셋을 이용하였습니다.

classification accuracy을 보면 기존 모델 skip-thought vector model과 매우 비슷한 것을 볼 수 있습니다. 비록 정확도가 조금 더 낮긴 하지만 저자들이 제안한 모델은 word-level decoder, LSTM이 필요하지 않아서 학습시키는 속도가 훨씬 빠른 장점이 있습니다.
참고 문헌, 사이트
Representation Learning with Contrastive Predictive Coding
While supervised learning has enabled great progress in many applications, unsupervised learning has not seen such widespread adoption, and remains an important and challenging endeavor for artificial intelligence. In this work, we propose a universal unsu
arxiv.org
Rethinking Representations: A Log-bilinear Model of Phonotactics
https://junia3.github.io/blog/InfoNCEpaper
Welcome to JunYoung's blog | Simple explanation of NCE(Noise Contrastive Estimation) and InfoNCE
해당 내용은 Representation Learning with Contrastive Predictive Coding에서 소개된 InfoNCE를 기준으로 그 loss term의 시작에 있는 InfoNCE에 대해 간단한 설명을 하고자 작성하게 되었다. 논문링크 InfoNCE는 contrastiv
junia3.github.io